
MySQL 23 How does MySQL ensure that data is not lost?
Solange die Redo-Logs und Binlogs dauerhaft auf der Festplatte gespeichert werden, kann sichergestellt werden, dass die Daten nach einem außergewöhnlichen Neustart von MySQL wiederhergestellt werden können. In diesem Artikel wird der Prozess des Schreibens von Binlogs und Redo-Logs in MySQL erläutert.
Der Schreibmechanismus von Binlogs
Die Logik des Schreibens von Binlogs ist relativ einfach: Während der Ausführung einer Transaktion werden die Logs zunächst in den Binlog-Cache geschrieben. Wenn die Transaktion bestätigt wird, wird der Binlog-Cache in die Binlog-Datei geschrieben.
Das Binlog einer Transaktion kann nicht aufgeteilt werden. Daher muss unabhängig von der Größe der Transaktion sichergestellt werden, dass sie in einem Schritt geschrieben wird. Dies betrifft die Speicherung des Binlog-Caches. Das System weist dem Binlog-Cache einen Speicherbereich zu, einen pro Thread. Der Parameter binlog_cache_size steuert die Größe des Speicherbereichs, den der Binlog-Cache in einem einzelnen Thread einnimmt. Wenn dieser Wert überschritten wird, muss der Cache vorübergehend auf die Festplatte geschrieben werden.
Bei der Transaktionsübermittlung schreibt der Executor die vollständige Transaktion aus dem Binlog-Cache in das Binlog und leert den Binlog-Cache.
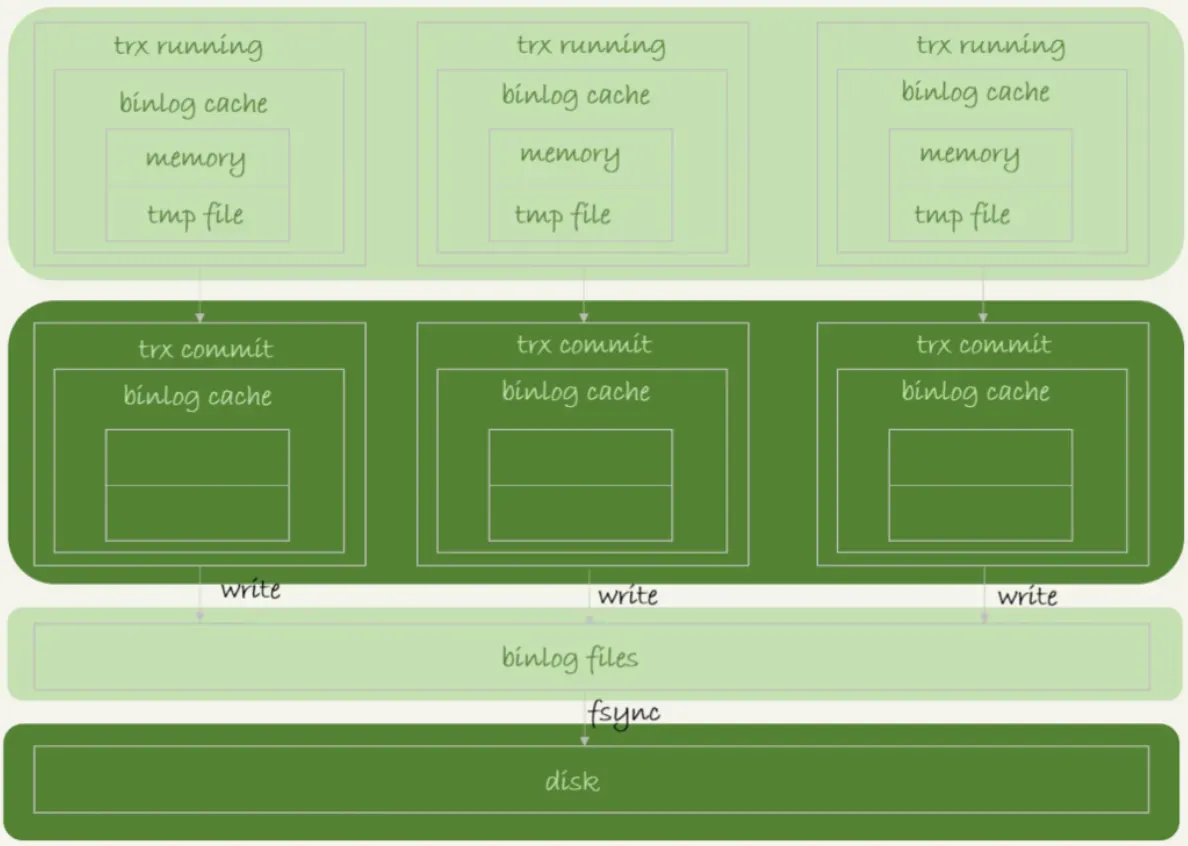
In der obigen Abbildung:
„write“ bezieht sich auf das Schreiben des Protokolls in den Seitencache des Dateisystems, was relativ schnell ist.
„fsync“ bezieht sich auf das dauerhafte Speichern der Daten auf der Festplatte.
Der Zeitpunkt für „write“ und „fsync“ wird durch den Parameter „sync_binlog“ gesteuert:
„sync_binlog=0“ bedeutet, dass bei jeder Transaktionsübermittlung nur „write“ ausgeführt wird, nicht jedoch „fsync“.
„sync_binlog=1“ bedeutet, dass bei jeder Transaktionsübermittlung „fsync“ ausgeführt wird.
sync_binlog=N>1 bedeutet, dass bei jeder Transaktionsübermittlung „write“ ausgeführt wird, aber erst nach N Transaktionen „fsync“.
Daher wird der Parameter in Szenarien mit IO-Engpässen in der Regel auf einen höheren Wert gesetzt. In realen Geschäftsszenarien wird unter Berücksichtigung der Kontrollierbarkeit des Log-Verlusts häufig ein Wert zwischen 100 und 1000 gewählt. Das Risiko dabei ist, dass bei einem unerwarteten Neustart des Hosts die Binlog-Protokolle der letzten N Transaktionen verloren gehen.
Schreibmechanismus des Redo-Logs
Während der Ausführung einer Transaktion wird das generierte Redo-Log zunächst in den Redo-Log-Puffer geschrieben. Der Inhalt des Redo-Log-Puffers muss nicht jedes Mal direkt auf die Festplatte geschrieben werden, kann aber auch auf die Festplatte geschrieben werden, bevor die Transaktion bestätigt wurde.
Um dieses Problem zu verstehen, muss man die drei möglichen Zustände des Redo-Logs kennen:
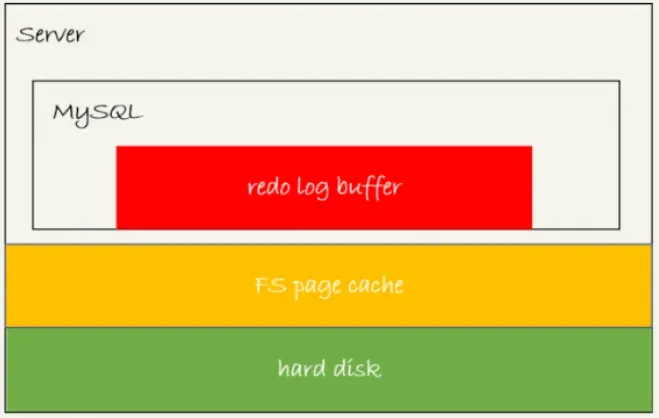
The three states are:
Exists in the redo log buffer, physically located in the MySQL process memory, i.e., the red area in the diagram;
Written to disk but not yet persisted (fsync), physically located in the file system's page cache, i.e., the yellow area in the diagram;
Persisted to disk, corresponding to the hard disk, i.e., the green area in the diagram.
Writing logs to the redo log buffer and writing to the page cache are both fast, but persisting to disk is much slower.
To control the redo log write strategy, InnoDB provides the innodb_flush_log_at_trx_commit parameter:
Setting it to 0 means that each transaction commit only leaves the redo log in the redo log buffer;
Setting it to 1 means that each transaction commit persists the redo log to disk;
Setting it to 2 means that each transaction commit only writes the redo log to the page cache.
InnoDB has a background thread that calls write every second to write the logs in the redo log buffer to the page cache of the file system, and then calls fsync to persist them to disk.
The redo logs generated during the execution of a transaction are also written directly to the redo log buffer, and these redo logs are also persisted to disk by the background thread. Therefore, the redo logs of an uncommitted transaction may already have been persisted to disk.
In addition to the background thread's once-per-second polling operation, there are two scenarios where the redo logs of an uncommitted transaction may be written to disk:
When the space occupied by the redo log buffer is about to reach half of innodb_log_buffer_size, the background thread will proactively write to disk. This write operation only calls write and does not call fsync;
When a transaction is committed in parallel, the redo log buffer of that transaction is also persisted to disk. Suppose transaction A is halfway through execution and has already written some redo logs to the buffer. At this point, transaction B from another thread commits. If innodb_flush_log_at_trx_commit=1, transaction B will persist all logs in the redo log buffer to disk, including those from transaction A.
The two-phase commit sequence involves preparing the redo log first, then writing the binlog, and finally committing the redo log. If innodb_flush_log_at_trx_commit=1, the redo log must be persisted once during the prepare phase because there is a crash recovery logic that depends on the prepared redo log + binlog. With the background polling once per second and the crash recovery logic, InnoDB assumes that the redo log does not need fsync during commit and only writes to the file system's page cache.
When referring to MySQL's “double 1” configuration, it means that both sync_binlog and innodb_flush_log_at_trx_commit are set to 1, meaning that a transaction must wait for two disk flushes before complete commit: one during redo log prepare and one during binlog.
At this point, there may be a question: if the TPS observed from MySQL is 20,000 per second, this would mean 40,000 disk writes per second, but the disk capacity is only around 20,000. How is a TPS of 20,000 achieved?
To explain this issue, we need to introduce the concept of Log Sequence Number (LSN). LSN is a monotonically increasing value that corresponds to each write point in the redo log. Each time a redo log of length length is written, the LSN value is incremented by length. LSN is also written to the InnoDB data page to ensure that the data page is not executed multiple times with duplicate redo logs.
The following diagram shows the process of three concurrent transactions completing the prepare phase and persisting the redo log buffer to disk, with corresponding LSN values of 50, 120, and 160:
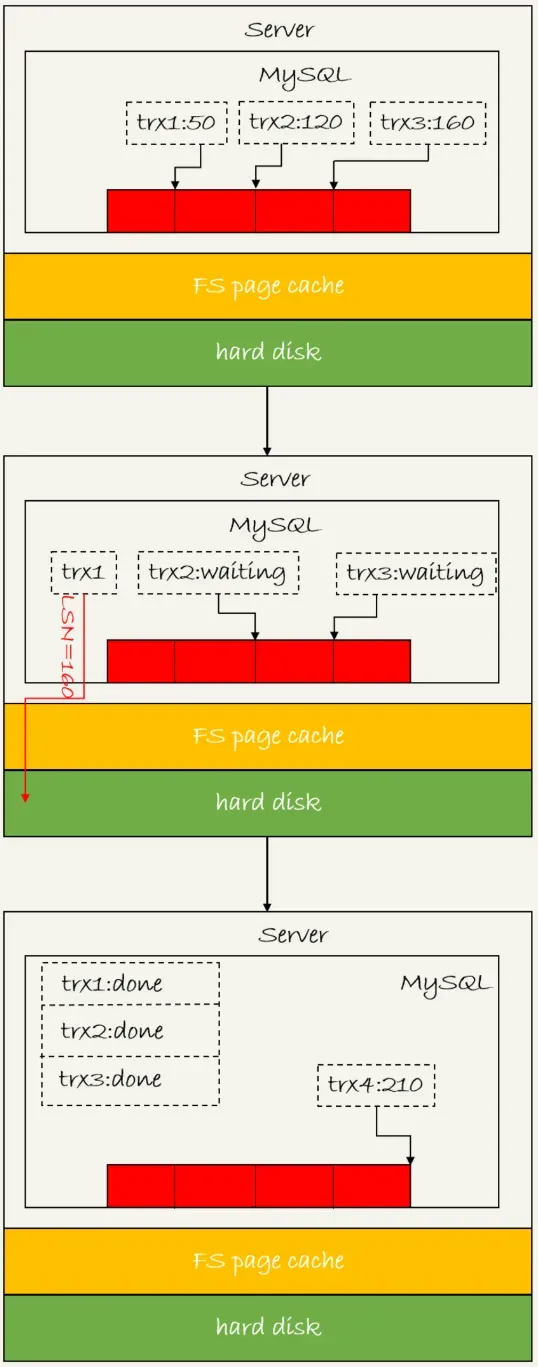
Explanation of the process:
trx1 arrives first and is selected as the leader of this group;
When trx1 starts writing to disk, there are three transactions in the group, and the LSN changes to 160;
When trx1 writes to disk, it carries LSN=160. By the time trx1 returns, all redo logs with LSN less than or equal to 160 have been persisted to disk;
At this point, trx2 and trx3 can return directly.
Therefore, in a single group commit, the more members in the group, the better the disk IOPS savings. In a concurrent update scenario, after the first transaction writes to the redo log buffer, the later fsync is called, the more group members there may be, and the better the IOPS savings.
To allow more group members to be included in a single fsync, MySQL also has optimizations. During the two-phase commit process, if the binlog is split into write and fsync, the entire two-phase commit process is actually:
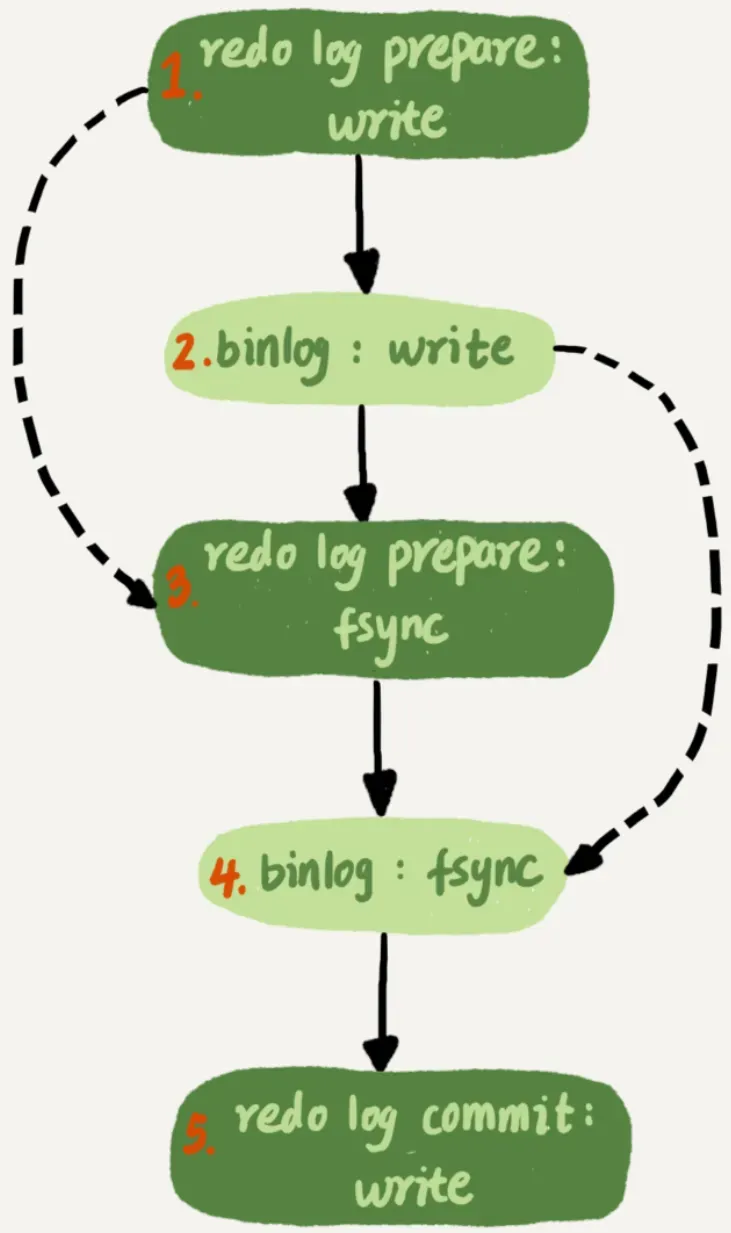
As mentioned above, MySQL has adjusted the time steps so that binlogs can also be committed in groups. When executing step 4, if the binlogs of multiple transactions have already been written, they are also persisted together, thereby reducing IOPS consumption.
However, step 3 is usually quick, so the interval between steps 2 and 4 is short, resulting in fewer binlogs being persisted together. Therefore, the effect of binlog group commits is typically not as good as that of redo logs. To improve the effectiveness of binlog group commits, you can set two parameters:
binlog_group_commit_sync_delay: specifies the delay in microseconds before calling fsync;
binlog_group_commit_sync_no_delay_count: specifies the number of times to accumulate before calling fsync.
In summary, the WAL mechanism primarily benefits from two aspects:
Redo logs and binlogs are written sequentially, which is faster than random writes;
The group commit mechanism significantly reduces disk IOPS consumption.
Finally, if MySQL encounters an IO performance bottleneck, how can performance be improved?
Set the binlog_group_commit_sync_delay and binlog_group_commit_sync_no_delay_count parameters to reduce the number of times binlog is written to disk;
Set sync_binlog to a value greater than 1, with the risk that binlog logs may be lost if the host loses power;
Set innodb_flush_log_at_trx_commit to 2, with the risk that data may be lost if the host loses power.